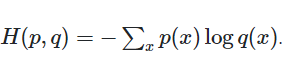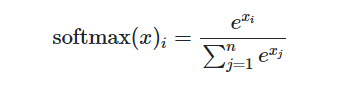REF:
- https://blog.statsbot.co/support-vector-machines-tutorial-c1618e635e93 (***) (very very important ... describe elaborately)
- https://www.quora.com/Why-is-a-support-vector-machine-called-a-machine (Why added machine in the last)
- https://www.youtube.com/watch?v=g8D5YL6cOSE
- https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47 ( svm algorithm and python code )
- https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/ (to understand pros and crons)
- https://en.wikipedia.org/wiki/Support-vector_machine (there lot of algorithm description )
- https://data-flair.training/blogs/svm-support-vector-machine-tutorial/ (SVM algorithm and python code)
- https://github.com/llSourcell/Classifying_Data_Using_a_Support_Vector_Machine/blob/master/support_vector_machine_lesson.ipynb (descripted by siraj svm and python code VVVVVI easily understandabe / https://www.youtube.com/watch?v=g8D5YL6cOSE) (for coding purpose see ref 4)
- https://towardsdatascience.com/support-vector-machines-intuitive-understanding-part-1-3fb049df4ba1 ( *******)
- https://towardsdatascience.com/support-vector-machines-svm-c9ef22815589 (basic idea about svm)
- https://medium.com/stupid-simple-ai-series/svm-and-kernel-svm-fed02bef1200
---------------------------------- vvvi start for SVM linear--------------------------------------
BOOK (andru ng book)
http://cs229.stanford.edu/notes/cs229-notes3.pdf
https://towardsdatascience.com/understanding-support-vector-machine-part-1-lagrange-multipliers-5c24a52ffc5e (important for understanding svm using legrance multiplier) (VVVVVI **************)(must read)
******************* ak sathe
https://www.youtube.com/watch?v=qF0aDJfEa4Y (convex optimization need to see before starting svm)
https://www.youtube.com/watch?v=05VABNfa1ds (describe the max W^2 (W square)) (VVVI )
https://www.youtube.com/watch?v=wBVSbVktLIY (Kernel tricks)
*********************
https://www.youtube.com/watch?v=_PwhiWxHK8o&t=1368s (boss video please to see this)
https://mccormickml.com/2013/04/16/trivial-svm-example/ (svm scoring function ******************)
https://towardsdatascience.com/support-vector-machines-svm-c9ef22815589 (basic idea about svm) (try to understand the soft margin(it about C) and hard margin )
https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47 ( svm algorithm and python code ) (this code is important for understanding matrix coding, not need to show siraj code )
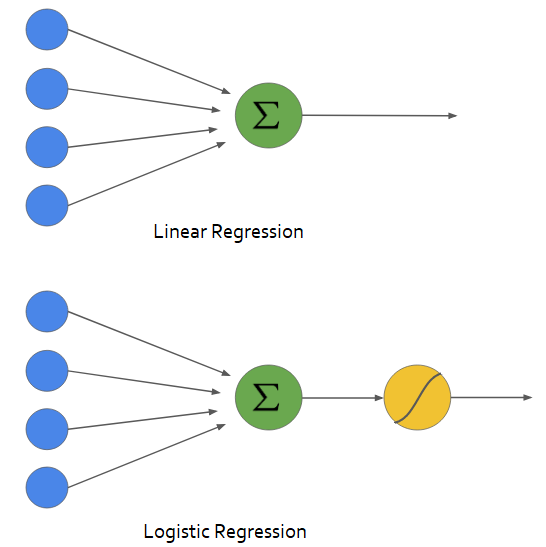
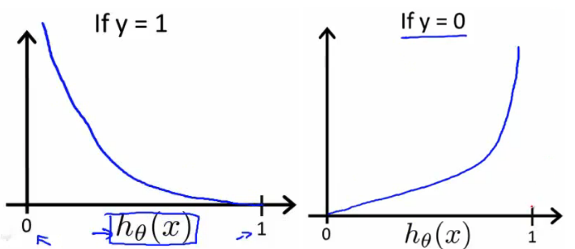
In logistic regression, we take the output of the linear function and squash the value within the range of [0,1] using the sigmoid function. If the squashed value is greater than a threshold value(0.5) we assign it a label 1, else we assign it a label 0. In SVM, we take the output of the linear function and if that output is greater than 1, we identify it with one class and if the output is -1, we identify is with another class. Since the threshold values are changed to 1 and -1 in SVM, we obtain this reinforcement range of values([-1,1]) which acts as margin.
understanding the cost function in SVM, just read the second part out of three part. it's describe better. (statement is ok)
So now comes the next question, what causes SVM to maximize the margin ‘m’ ? The answer lies in optimizing the cost/ loss function that was discussed in Part #1.
(**************** it has three part )
- https://towardsdatascience.com/support-vector-machines-intuitive-understanding-part-1-3fb049df4ba1 (part 1)
- https://towardsdatascience.com/support-vector-machines-intuitive-understanding-part-2-1046dd449c59 (part 2)
- https://www.intmath.com/plane-analytic-geometry/perpendicular-distance-point-line.php (perpendicular distance equation proved)
- https://www.freemathhelp.com/numerator-denominator.html (denominator)
- diverges just opposite of converge which means same value will not generate after some time.
Normalization:
The word “normalization” is used informally in statistics, and so the term normalized data can have multiple meanings. In most cases, when you normalize data you eliminate the units of measurement for data, enabling you to more easily compare data from different placesWeights can be adjusted by dividing the weight by the mean of weights. The relative values of the weights are not changed, but they are adjusted so that the mean is 1, and the sum of weights equals the N of cases
(Andru Ng lecture about Support vector machine) (**********************)

- Video Lectures: Learning from Data by Yaser Abu-Mostafa. Lectures from 14 to 16 talk about SVMs and kernels. I’d also highly recommend the whole series if you’re looking for an introduction to ML, it maintains an excellent balance between math and intuition.
- Book: The Elements of Statistical Learning — Trevor Hastie, Robert Tibshirani, Jerome Friedman.Chapter 4 introduces the basic idea behind SVMs, while Chapter 12 deals with it comprehensively.
SUPORT vector machine implementation:
- https://www.codeproject.com/Articles/1267445/An-Introduction-to-Support-Vector-Machine-SVM-and
- https://mccormickml.com/2013/04/16/trivial-svm-example/
- https://en.wikipedia.org/wiki/Sequential_minimal_optimization (SMO descripotion better)
- http://cs229.stanford.edu/materials/smo.pdf (description + code vvvvviiiiii)
- https://shuzhanfan.github.io/2018/05/understanding-mathematics-behind-support-vector-machines/ (boss theory)
- http://www.ccs.neu.edu/home/vip/teach/MLcourse/6_SVM_kernels/lecture_notes/svm/svm.pdf (A to Z about svm)
- https://www.pyimagesearch.com/2016/09/05/multi-class-svm-loss/ (According to rossi san example)
https://towardsdatascience.com/common-loss-functions-in-machine-learning-46af0ffc4d23 (Hindge loss ***********************)
---------------------------------- start for SVM non linear info--------------------------------------
Ref:
- https://www.geeksforgeeks.org/ml-using-svm-to-perform-classification-on-a-non-linear-dataset/ (example with figure and scikit code)
- https://www.kdnuggets.com/2016/06/select-support-vector-machine-kernels.html
- https://towardsdatascience.com/support-vector-machines-svm-c9ef22815589 (basic idea about svm)
Why kernel is important:
https://towardsdatascience.com/kernel-function-6f1d2be6091 (VVI ***) (
How does it work? please read this section
)In machine learning, a “kernel” is usually used to refer to the kernel trick, a method of using a linear classifier to solve a non-linear problem.
SVM algorithms use a set of mathematical functions that are defined as the kernel. The function of kernel is to take data as input and transform it into the required form. Different SVM algorithms use different types of kernel functions. These functions can be different types. For example linear, nonlinear, polynomial, radial basis function (RBF), and sigmoid.
ref: https://data-flair.training/blogs/svm-kernel-functions/
MAin Kernel: (https://www.youtube.com/watch?v=FCUBwP-JTsA&list=PLNeKWBMsAzboNdqcm4YY9x7Z2s9n9q_Tb&index=6) (this video discuss about how to use kernel and compare the logistic regression and svm) (must watch)
- linear kernel (no kernel)
- when feature/ column large then use linear kernel.
- linear kernel is called no kernel. that means that time don't change the dimention
- Gaussian kernel / Radial basis funtion (RBF) kernel
- when feature is less but data is huge then use gaussian kernel
- Do perform feature scaling before implementing Gaussian kernel
many off-the-shelf-kernel:
- polynomial
- string kernel
- chi square kernel
- histogram intersection kernel

Gaussian kernel
- https://datascience.stackexchange.com/questions/17352/why-do-we-use-a-gaussian-kernel-as-a-similarity-metric (why measure exponential similarity)
- use feature scalling before using gaussian kernel