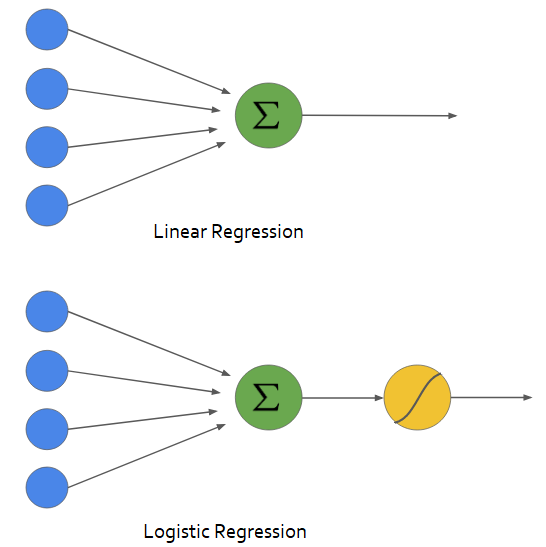
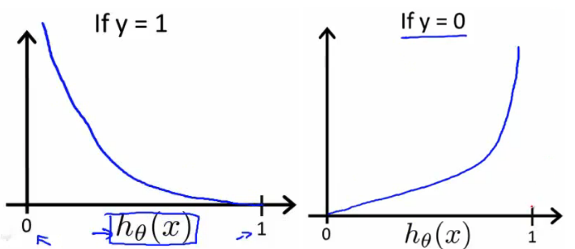
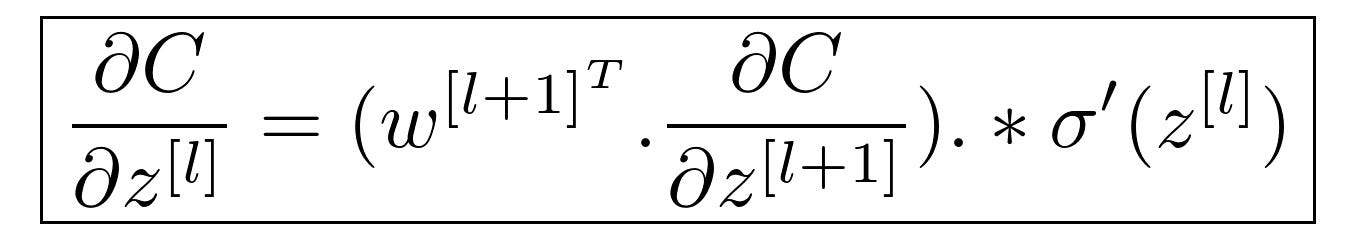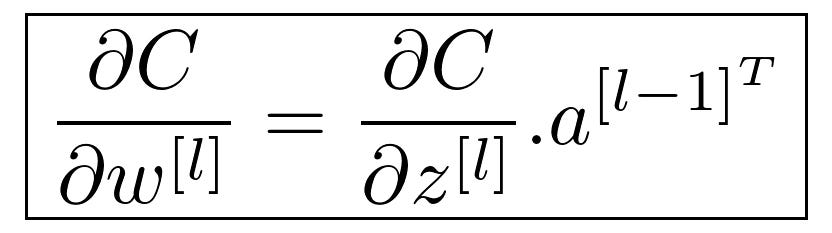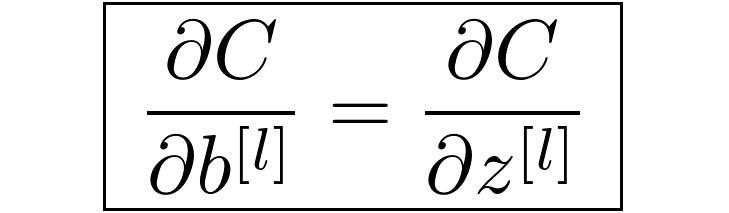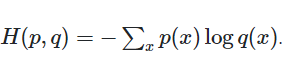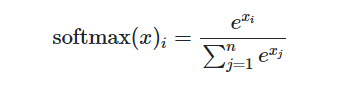Ref:
Rgularization:
- https://medium.com/@dk13093/lasso-and-ridge-regularization-7b7b847bce34
- https://towardsdatascience.com/l1-and-l2-regularization-methods-ce25e7fc831c
- https://towardsdatascience.com/intuitions-on-l1-and-l2-regularisation-235f2db4c261
By
reducing the sum of absolute values of the coefficients, what Lasso
Regularization (L1 Norm) does is to reduce the number of features in the
model altogether to predict the target variable.
On
the other hand, by reducing the sum of square of coefficients, Ridge
Regularization (L2 Norm) doesn’t necessarily reduce the number of
features per se, but rather reduces the magnitude/impact that each
features has on the model by reducing the coefficient value.
So
simply put, both regularization does indeed prevent the model from
overfitting, but I would like to think of Lasso Regularization as
reducing the quantity of features while Ridge Regularization as reducing
the quality of features. In essence, both types of reductions are
needed, and therefore it makes much more sense why ElasticNet
(combination of Lasso and Ridge Regularization) would be the ideal type
of regularization to perform on a model.
https://stats.stackexchange.com/questions/45643/why-l1-norm-for-sparse-models/159379 (VVVVVVIII *******************) (to understand the L1 Norm does is to reduce the number of features in the model and L2 Norm doesn’t necessarily reduce the number of features per) (second answer)
With a sparse model, we think of a model where many of the weights are 0. Let us therefore reason about how L1-regularization is more likely to create 0-weights.
Consider a model consisting of the weights
.
With L1 regularization, you penalize the model by a loss function
= .
With L2-regularization, you penalize the model by a loss function
= If using gradient descent, you will iteratively make the weights change in the opposite direction of the gradient with a step size
multiplied with the gradient. This means that a more steep gradient will make us take a larger step, while a more flat gradient will make us take a smaller step. Let us look at the gradients (subgradient in case of L1):
, where
Need to understand the question vvvviiiiii.
1.Why vanishing gradients is problematic for training deep neural networks? How does using ReLU
alleviate this problem?
2. Why is bias term necessary in neural network?
3. Explain the bias-variance trade-off.
4. How does L1/L2 regularization reduce overfitting?
5. Explain how dropout allows us to train an ensemble of neural network simultaneously.
6. How does L1 regularization create sparse model?
7. If number of neurons is fixed, is it better to make a neural network deeper (more layer) or wider
(more neurons per layer)?
8. What is the effect of learning rate for training neural network?